문제
- Ultimate Car Driving Online 스크린샷에서
속도 부분만 캡쳐하여 숫자를 알아내고자 한다. - 작은 CRNN 모델을 학습시켜 해결하였다.
전반적인 과정
- 여러 폰트로 숫자가 표시된 이미지를 생성하여
train dataset을 만든다. - CRNN을 학습시킨다.
- Ultimate Car Driving Online 를 플레이하며
스크린샷을 찍어 test dataset을 만든다. - 학습한 CRNN로 test dataset을 예측해본다.
- 예측결과가 잘 나오지 않았다면
처음부터 부분 부분 수정해가며
위 과정을 반복한다.
실험환경
- OS
- Windows
(화면 캡쳐할 때 Windows API를 사용하므로
다른 OS는 다른 방법을 사용하여야 한다)
- Windows
- miniconda3
문자 dataset 생성기
- 설명
- 여러 폰트와 옵션을 사용하여 문자가 포함된
여러 이미지를 생성한다.
- 여러 폰트와 옵션을 사용하여 문자가 포함된
- repository
- 주소
- 원본 repository
- 수정사항
- 숫자 이미지 생성 시 숫자 길이를 최소 1, 최대 4로 변경하였다.
- 몇몇 폰트를 추가하였다.
- 환경 구축
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# anaconda prompt를 실행하고 아래 명령 입력 # 가상환경 설치 conda create -n trdg python=3.10 # 가상환경 활성화 conda activate trdg # git clone git clone https://github.com/a3magic3pocket/TextRecognitionDataGenerator.git # repository 위치로 이동 cd TextRecognitionDataGenerator # 의존성 패키지 설치 pip install -r requirements.txt # run.py 위치로 이동 cd trdg
- 데이터 생성
- 설명
- 1~4개의 숫자가 랜덤으로 찍힌 이미지들을 10000개 생성한다.
- 인자설명
- 공식문서
- run.py에 더 자세한 인자 설명이 있다.
- 명령
1 2 3 4 5 6 7 8 9 10 11
## -- 인자 설명 -- ## # -c [생성할 이미지 수] # --output_dir [생성된 이미지를 저장할 디렉토리 명] # -rs [랜덤 시퀀스, 문자열이 랜덤으로 표시되어 이미지가 생성됨] # -num [랜덤으로 생성하는 문자열이 숫자로 제한] # -w [단어 수, 여기서는 1로 고정] # -fi [이미지 여백을 타이트하게 지정] # -im [이미지 모드, L은 8-bit grayscale image를 의미] # -t [처리 시 사용할 스레드 수] ############## python run.py -c 10000--output_dir outputs -rs -num -w 1 -fi -im L -t 4
- 예시
- outputs 디렉토리 하위에 아래 이미지 들이 생성된 것을 볼 수 있다.

- 설명
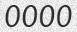

CRNN
- 설명
- Building a custom OCR using pytorch 글을 참고하여 CRNN 모델을 구축한다.
- CRNN을 모델이 작아서 그런지 CPU를 사용해도 금방 학습되기에
우선 CPU 기준으로 작성하였다.
(이미지 20000 개 1 epoch 기준 약 5분)
- repository
- 주소
- 원본 repository
- 수정사항
- 원본 repository에서 CRNN의 학습(train) 및 추정(eval) 부분만
추출한다. - nClasses을 len(alphabet) + 1로 수정하였다.
- lr(learning rate)을 0.0001로 수정하였다.
- 원본 repository에서 CRNN의 학습(train) 및 추정(eval) 부분만
- 환경구축
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# anaconda prompt를 실행하고 아래 명령 입력 # 가상환경 설치 # colab과 pytorch를 고려하여 3.9로 설치한다. conda create -n crnn python=3.9 # 가상환경 활성화 conda activate crnn # git clone git clone https://github.com/a3magic3pocket/crnn.git # repository 위치로 이동 cd crnn # 의존성 패키지 설치 pip install -r requirements.txt
- 학습 데이터 이동
- 학습데이터가 담긴 TextRecognitionDataGenerator/trdg/outputs 디렉토리를
잘라내기(Ctrl + x)한 뒤
crnn/data 하위로 붙여넣기(Ctrl + v)한다. - crnn/data/outputs 디렉토리 명을 crnn/data/images로 변경한다.
- 학습데이터가 담긴 TextRecognitionDataGenerator/trdg/outputs 디렉토리를
- 하이퍼파라미터 조작
- train.py 을 에디터로 연다.
- args[‘epochs’]를 5로 조정한다.
- 학습 시작
1
python train.py
- 학습 결과
- 0 epoch 정도에서는 train_loss만 조금씩 감소하며
train_ca(character accuracy)와 train_wa(word accuracy)는
0으로 나타난다. - 1~4 epoch 정도에서부터 train_ca, train_wa가 상승하기 시작하다
마지막에는 train_ca=90, train_wa=0.8 이상을 달성한다. - 5 epcoh에는 대부분 train_ca=99, train_wa=0.9이상에 도달한다.
- 0 epoch 정도에서는 train_loss만 조금씩 감소하며
- validation 결과
- val_loss=0.00554~0.05
- val_ca=97~100
- val_wa=0.9~1
test dataset 만들기
- 설명
- Ultimate Car Driving Online 을 플레이하며
일정 시간마다 스크린샷을 찍는다. - 스크린샷에서 속도 부분만 cropped 후
몇 가지 후보정을 한다. - (!주의)윈도우 API를 사용하므로 윈도우에서만 동작한다.
- Ultimate Car Driving Online 을 플레이하며
- repository
- 환경구축
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# anaconda prompt를 실행하고 아래 명령 입력 # 가상환경 설치 conda create -n auto python=3.10 # 가상환경 활성화 conda activate auto # git clone git clone https://github.com/a3magic3pocket/autonomous-driving.git # repository 위치로 이동 cd autonomous-driving # 의존성 패키지 설치 pip install -r requirements.txt
- Ultimate Car Driving Online 설치
- 크롬을 켠다
- Ultimate Car Driving Online 로 접속하여
확장프로그램을 다운로드 후 설치한다. - 확장프로그램(이하 car앱)을 실행시킨다.
- 수집 실행
- 명령
1 2 3 4 5
# collect.py 위치로 이동 cd data_collection # 실행 python collect.py
- 실행 명령을 내리면 car앱 창이 focus 잡힌다.
- 대략적으로 매 초마다 car앱창이 스크린샷으로 찍혀
data_collection/img 디렉토리에 저장된다. - car앱에서 방향키를 눌러 차를 운전하여
다양한 속도가 스크린샷에 표시되도록 한다.
- 명령
- 정제 실행
- 설명
- 입력 받은 스크린샷에서 속도 부분만 잘라낸다.
- 잘라낸 이미지를 grayscale로 변환한다.
- 원본 이미지는 글씨가 흰색, 배경이 검정색이다.
이를 반전시켜 글씨가 검정색, 배경이 흰색으로 만든다. - 이미지에서 숫자 부분만 표시하도록 하기 위해
임계값(threshold)를 두고
임계값 이상이면 0(검정색), 임계값 미만이면 255(흰색)로
수정한다.
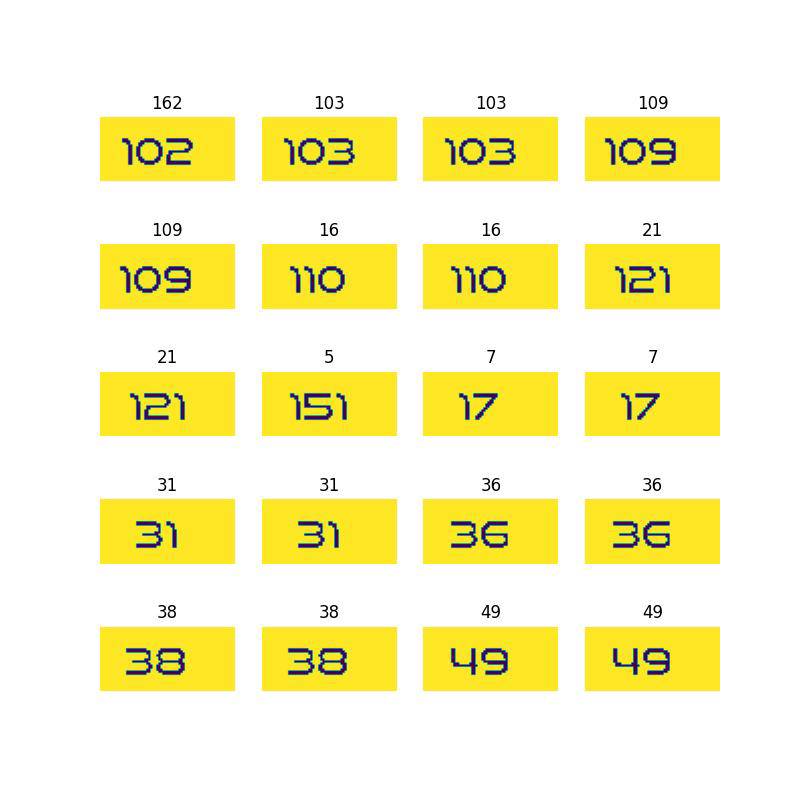
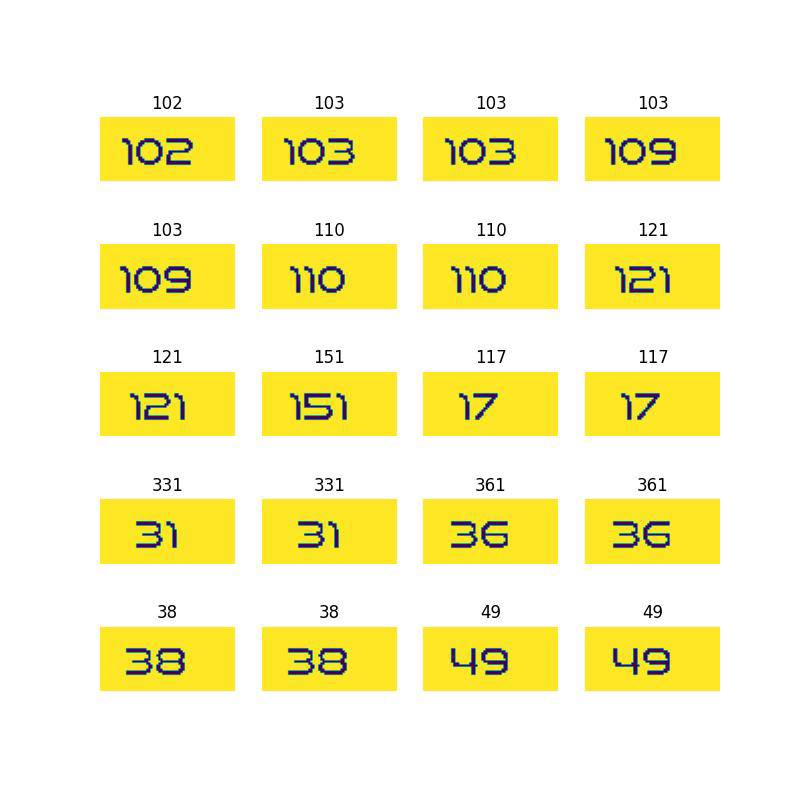
- 예시
- 원본 속도 이미지
- 정제 결과
- 원본 속도 이미지
- 명령
1 2 3 4 5
# refine.py 위치로 이동 cd data_collection # 실행 python refine.py
- 라벨 지정
- refined_img 디렉토리에 정제 결과가 저장된다.
- TextRecognitionDataGenerator에서 사용하는 라벨링 방법대로
정제 결과 이미지에 라벨링을 수작업으로 해줘야 한다. - 라벨을 파일명에 표시하며 규칙은 아래와 같다.
[정답]_[랜덤숫자].[확장자] - 예시
- 이미지
- 파일명
- 0000_1234.png
- 이미지
- 설명

CRNN test 해보기
- 설명
- eval.py를 실행하여 정제한 실제 데이터 통한 테스트를 진행한다.
- 진행
- autonomous-driving/data_collection/refined_img 디렉토리를
crnn/data/test로 이름바꿔 이동시킨다(move)
- autonomous-driving/data_collection/refined_img 디렉토리를
- 하이퍼 파라미터 조정
- crnn/eval.py를 에디터로 연다.
- args[“imgdir”] 값을 “test”로 바꾼다.
- 명령
1 2 3 4 5 6 7 8
# 가상환경 활성화 conda activate crnn # eval.py로 이동 cd crnn # 실행 python eval.py
- 결과
- Character Accuracy: 43.23
- Word Accuracy: 0.12
개선1: 학습 데이터에서 문자열 조작
- 개요
- 학습 데이터에서 기울기(skew)와 흐림(blur), 왜곡(distortion) 값을
랜덤으로 조정하여 이미지를 생성한 후 다시 학습해본다.
- 학습 데이터에서 기울기(skew)와 흐림(blur), 왜곡(distortion) 값을
- TextRecognitionDataGenerator으로 학습 데이터 생성
- 명령
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## -- 인자 설명 -- ## # -c [생성할 이미지 수] # --output_dir [생성된 이미지를 저장할 디렉토리 명] # -rs [랜덤 시퀀스, 문자열이 랜덤으로 표시되어 이미지가 생성됨] # -num [랜덤으로 생성하는 문자열이 숫자로 제한] # -w [단어 수, 여기서는 1로 고정] # -fi [이미지 여백을 타이트하게 지정] # -im [이미지 모드, L은 8-bit grayscale image를 의미] # -t [처리 시 사용할 스레드 수] # -rk [랜덤 기울기(skew)] # -rbl [랜덤 흐림(blur)] # -d [왜곡(distortion)], 3은 랜덤을 의미 # -do [왜곡방향, 2는 Vertical, Horizontal 모두를 의미] ############## python run.py -c 10000 --output_dir outputs -rs -num -w 1 -fi -im L -t 4 -rk -rbl -d 3 -do 2
- 예시
- 결과
- TextRecognitionDataGenerator/trdg/outputs에 저장됨
- 명령
- CRNN으로 학습
- 데이터 준비
- TextRecognitionDataGenerator/trdg/outputs를 잘라내기(Ctrl+x)한 후
crnn/data/manipulated 로 이름바꿔 붙여넣기(Ctrl+v)
- TextRecognitionDataGenerator/trdg/outputs를 잘라내기(Ctrl+x)한 후
- weight 저장
- weight는 계속 갱신되므로 기존 checkpoint를 이름바꿔 보관한다.
- checkpoints/exp1/best.ckpt를 복사하여
checkpoints/exp1/0_origin_best.ckp를 생성
- 하이퍼 파라미터 조정
- crnn/train.py를 에디터로 연다.
- args[‘imgdir’]를 manipulated로 변경한다.
- args[‘epochs’]를 5 -> 6으로 늘려준다.
(checkpoint에 epochs도 저장되어 있어
이어서 학습할 때 (args[‘resume’] == True)
기존 epochs보다 숫자가 낮으면 학습하지 않는다) - args[‘force_save’]를 True로 변경한다.
(기존에는 early stopping이 적용되어 있어
이어서 학습할 때 (args[‘resume’] == True)
기존 weight의 loss보다 현재 epoch의 loss가 낮지 않으면
저장되지 않는다.
이를 무시하고 강제로 저장하기 위해
force_save를 True로 지정한다.)
- 명령
1
python train.py
- 데이터 준비
- CRNN으로 테스트
- 명령
1
python eval.py
- 결과
- Character Accuracy: 70.83
- Word Accuracy: 0.53
- 명령


개선2: 특정 폰트를 지정해서 학습 데이터 생성
- 개요
- 학습 데이터의 문자열에 여러 조작을 가하는 것만으로
상당히 정확도가 상승하였다. - 이를 통해 아예 이미지에 표시되는 폰트로만
학습데이터를 구성하면 더 효과적일 것이라고 추정하였다. - 해당 이미지와 가장 유사한 폰트를 찾아본 결과,
venus rising 폰트가 가장 유사하다고 판단하였다. - venus rising 폰트로만 학습데이터를 만들고
학습시켜본다.
- 학습 데이터의 문자열에 여러 조작을 가하는 것만으로
- TextRecognitionDataGenerator으로 학습 데이터 생성
- venus rising 폰트는 이미 repository에 추가되어 있을 것이다.
- 없을 경우, venus rising에서 폰트를 다운로드 받고
TextRecognitionDataGenerator/trdg/fonts/custom/venus-rising-rg.otf로
이름 바꿔 붙여넣기 한다. - 명령
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## -- 인자 설명 -- ## # -ft [생성할 이미지의 문자 폰트 경로] # -c [생성할 이미지 수] # --output_dir [생성된 이미지를 저장할 디렉토리 명] # -rs [랜덤 시퀀스, 문자열이 랜덤으로 표시되어 이미지가 생성됨] # -num [랜덤으로 생성하는 문자열이 숫자로 제한] # -w [단어 수, 여기서는 1로 고정] # -fi [이미지 여백을 타이트하게 지정] # -im [이미지 모드, L은 8-bit grayscale image를 의미] # -t [처리 시 사용할 스레드 수] # -rk [랜덤 기울기(skew)] # -rbl [랜덤 흐림(blur)] # -d [왜곡(distortion)], 3은 랜덤을 의미 # -do [왜곡방향, 2는 Vertical, Horizontal 모두를 의미] python run.py -ft fonts/custom/venus-rising-rg.otf -c 10000 --output_dir outputs -rs -num -w 1 -fi -im L -t 4
- 예시
- 결과
- TextRecognitionDataGenerator/trdg/outputs에 저장됨
- CRNN으로 학습
- 데이터 준비
- TextRecognitionDataGenerator/trdg/outputs를 잘라내기(Ctrl+x)한 후
crnn/data/venus로 이름바꿔 붙여넣기(Ctrl+v)
- TextRecognitionDataGenerator/trdg/outputs를 잘라내기(Ctrl+x)한 후
- weight 저장
- weight는 계속 갱신되므로 기존 checkpoint를 이름바꿔 보관한다.
- checkpoints/exp1/best.ckpt를 복사하여
checkpoints/exp1/1_manipulated_best.ckp를 생성
- 하이퍼 파라미터 조정
- crnn/train.py를 에디터로 연다.
- args[‘imgdir’]를 venus로 변경한다.
- args[‘epochs’]를 6 -> 7으로 늘려준다.
- args[‘force_save’]를 True로 변경한다.
- 명령
1
python train.py
- 데이터 준비
- CRNN으로 테스트
- 명령
1
python eval.py
- 결과
- Character Accuracy: 83.33
- Word Accuracy: 0.66
- 명령

개선3: venus 문자에 조작(skew, blur, distortion)을 가해서 학습 데이터 생성
- 개요
- venus 문자에 조작을 가해 학습 데이터를 생성해본다.
- 전반적은 과정은 개선1, 개선2와 동일하므로
데이터 생성 명령과 모델 학습 후 테스트 결과만 표기하도록 한다.
- TextRecognitionDataGenerator으로 학습 데이터 생성
- 명령
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## -- 인자 설명 -- ## # -ft [생성할 이미지의 문자 폰트 경로] # -c [생성할 이미지 수] # --output_dir [생성된 이미지를 저장할 디렉토리 명] # -rs [랜덤 시퀀스, 문자열이 랜덤으로 표시되어 이미지가 생성됨] # -num [랜덤으로 생성하는 문자열이 숫자로 제한] # -w [단어 수, 여기서는 1로 고정] # -fi [이미지 여백을 타이트하게 지정] # -im [이미지 모드, L은 8-bit grayscale image를 의미] # -t [처리 시 사용할 스레드 수] # -rk [랜덤 기울기(skew)] # -rbl [랜덤 흐림(blur)] # -d [왜곡(distortion)], 3은 랜덤을 의미 # -do [왜곡방향, 2는 Vertical, Horizontal 모두를 의미] python run.py -ft fonts/custom/venus-rising-rg.otf -c 10000 --output_dir outputs -rs -num -w 1 -fi -im L -t 4 -rk -rbl -d 3 -do 2
- 예시
- 명령
- CRNN으로 테스트
- 결과
- Character Accuracy: 83.33
- Word Accuracy: 0.66
- 결과

개선4: 원본 숫자 이미지로 폰트를 생성하여 학습 데이터 생성
- 개요
- venus 폰트와 원본 숫자 이미지는 묘하게 다른 부분이 있다.
- 아예 원본 숫자 이미지로 폰트를 만들어서 학습시키면
좋을 것 같아 폰트를 만들어서 처리해보았다.
- 폰트 생성법
- How to Create a Font
- 위 글의 방법으로 직접 폰트를 생성한다.
- 숫자를 제외한 나머지 영문자는 손글씨로 작성하고
숫자 부분은 testset의 이미지를 캡쳐하여
채워 넣는다. - 생성된 폰트는
TextRecognitionDataGenerator/trdg/fonts/custom/my-font-regular.otf에
저장되어있다.
- TextRecognitionDataGenerator으로 학습 데이터 생성
- 명령
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## -- 인자 설명 -- ## # -ft [생성할 이미지의 문자 폰트 경로] # -c [생성할 이미지 수] # --output_dir [생성된 이미지를 저장할 디렉토리 명] # -rs [랜덤 시퀀스, 문자열이 랜덤으로 표시되어 이미지가 생성됨] # -num [랜덤으로 생성하는 문자열이 숫자로 제한] # -w [단어 수, 여기서는 1로 고정] # -fi [이미지 여백을 타이트하게 지정] # -im [이미지 모드, L은 8-bit grayscale image를 의미] # -t [처리 시 사용할 스레드 수] # -rk [랜덤 기울기(skew)] # -rbl [랜덤 흐림(blur)] # -d [왜곡(distortion)], 3은 랜덤을 의미 # -do [왜곡방향, 2는 Vertical, Horizontal 모두를 의미] python run.py -ft fonts/custom/my-font-regular.otf -c 10000 --output_dir outputs -rs -num -w 1 -fi -im L -t 4
- 예시
- CRNN으로 테스트
- 결과
- Character Accuracy: 86.46
- Word Accuracy: 0.72
- 결과
- 명령
개선5: myfont로 문자에 조작(skew, blur, distortion)을 가해서 학습 데이터 생성
- TextRecognitionDataGenerator으로 학습 데이터 생성
- 명령
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
## -- 인자 설명 -- ## # -ft [생성할 이미지의 문자 폰트 경로] # -c [생성할 이미지 수] # --output_dir [생성된 이미지를 저장할 디렉토리 명] # -rs [랜덤 시퀀스, 문자열이 랜덤으로 표시되어 이미지가 생성됨] # -num [랜덤으로 생성하는 문자열이 숫자로 제한] # -w [단어 수, 여기서는 1로 고정] # -fi [이미지 여백을 타이트하게 지정] # -im [이미지 모드, L은 8-bit grayscale image를 의미] # -t [처리 시 사용할 스레드 수] # -rk [랜덤 기울기(skew)] # -rbl [랜덤 흐림(blur)] # -d [왜곡(distortion)], 3은 랜덤을 의미 # -do [왜곡방향, 2는 Vertical, Horizontal 모두를 의미] python run.py -ft fonts/custom/my-font-regular.otf -c 10000 --output_dir outputs -rs -num -w 1 -fi -im L -t 4 -rk -rbl -d 3 -do 2
- 예시
- CRNN으로 테스트
- 결과
- Character Accuracy: 86.98
- Word Accuracy: 0.72
- 결과
- 명령
개선6: myfont의 글자(chracter) 간 간격을 좁혀서 학습 데이터 생성
- TextRecognitionDataGenerator으로 학습 데이터 생성
- 명령
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
## -- 인자 설명 -- ## # -ft [생성할 이미지의 문자 폰트 경로] # -c [생성할 이미지 수] # --output_dir [생성된 이미지를 저장할 디렉토리 명] # -rs [랜덤 시퀀스, 문자열이 랜덤으로 표시되어 이미지가 생성됨] # -num [랜덤으로 생성하는 문자열이 숫자로 제한] # -w [단어 수, 여기서는 1로 고정] # -fi [이미지 여백을 타이트하게 지정] # -im [이미지 모드, L은 8-bit grayscale image를 의미] # -t [처리 시 사용할 스레드 수] # -rk [랜덤 기울기(skew)] # -rbl [랜덤 흐림(blur)] # -d [왜곡(distortion)], 3은 랜덤을 의미 # -do [왜곡방향, 2는 Vertical, Horizontal 모두를 의미] # -cs [글자 간격, 단위 픽셀] python run.py -ft fonts/custom/my-font-regular.otf -c 10000 --output_dir outputs -rs -num -w 1 -fi -im L -cs -2 -t 4
- 예시
- CRNN으로 테스트
- 결과
- Character Accuracy: 74.48
- Word Accuracy: 0.53
- 결과
- 명령

개선7: myfont의 기울기를 지정하여 학습 데이터 생성
- 개요
- 글자 간 간격을 좁혔더니 정확도가 더 낮아졌다.
- 글자 간 간격보다 기울기를 조정하는 것이 더 효과적일 것 같아
15 또는 345 도(degree)로 기울여서 학습데이터를 생성해본다.
- TextRecognitionDataGenerator으로 학습 데이터 생성
- 명령
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## -- 인자 설명 -- ## # -ft [생성할 이미지의 문자 폰트 경로] # -c [생성할 이미지 수] # --output_dir [생성된 이미지를 저장할 디렉토리 명] # -rs [랜덤 시퀀스, 문자열이 랜덤으로 표시되어 이미지가 생성됨] # -num [랜덤으로 생성하는 문자열이 숫자로 제한] # -w [단어 수, 여기서는 1로 고정] # -fi [이미지 여백을 타이트하게 지정] # -im [이미지 모드, L은 8-bit grayscale image를 의미] # -t [처리 시 사용할 스레드 수] # -rk [랜덤 기울기(skew)] # -rbl [랜덤 흐림(blur)] # -d [왜곡(distortion)], 3은 랜덤을 의미 # -do [왜곡방향, 2는 Vertical, Horizontal 모두를 의미] # -cs [글자 간격, 단위 픽셀] python run.py -ft fonts/custom/my-font-regular.otf -c 5000 --output_dir outputs -rs -num -w 1 -fi -im L -t 4 -k 15 python run.py -ft fonts/custom/my-font-regular.otf -c 5000 --output_dir outputs -rs -num -w 1 -fi -im L -t 4 -k 345
- 예시
- CRNN으로 테스트
- 결과
- Character Accuracy: 67.19
- Word Accuracy: 0.34
- 결과
- 명령
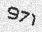

개선8: myfont의 가로 측 여백을 넓게 하여 학습 데이터 생성
- 개요
- 기울기를 조정했더니 정확도가 더 낮아졌다.
- test dataset의 가로 측 여백이 많기에
학습 데이터에도 가로 측 여백을 늘려보기로 하였다.
- TextRecognitionDataGenerator으로 학습 데이터 생성
- 명령
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
## -- 인자 설명 -- ## # -ft [생성할 이미지의 문자 폰트 경로] # -c [생성할 이미지 수] # --output_dir [생성된 이미지를 저장할 디렉토리 명] # -rs [랜덤 시퀀스, 문자열이 랜덤으로 표시되어 이미지가 생성됨] # -num [랜덤으로 생성하는 문자열이 숫자로 제한] # -w [단어 수, 여기서는 1로 고정] # -fi [이미지 여백을 타이트하게 지정] # -im [이미지 모드, L은 8-bit grayscale image를 의미] # -t [처리 시 사용할 스레드 수] # -rk [랜덤 기울기(skew)] # -rbl [랜덤 흐림(blur)] # -d [왜곡(distortion)], 3은 랜덤을 의미 # -do [왜곡방향, 2는 Vertical, Horizontal 모두를 의미] # -cs [글자 간격, 단위 픽셀] python run.py -ft fonts/custom/my-font-regular.otf -c 10000 --output_dir outputs -rs -num -w 1 -fi -im L -t 4 -wd 100
- 예시
- CRNN으로 테스트
- 결과
- Character Accuracy: 100.0
- Word Accuracy: 1.00
- 결과
- 명령
번외: train.py의 transforms에 Padding과 skewing 추가하기
- 개요
- 간단히 가로 축 여백 추가(Padding)과 기울기(skewing)만
추가해도 학습이 잘 되는지 궁금해졌다. - 학습 transforms에 Padding과 skewing을 추가한다.
- 간단히 가로 축 여백 추가(Padding)과 기울기(skewing)만
- 학습 데이터
- myfont 학습 데이터를 사용
- CRNN 학습
- 얼마나 유효한지 확인하기 위해 처음부터 학습
- 5 epoch 동안 학습
- CRNN으로 테스트
- 결과
- Character Accuracy: 56.57
- Word Accuracy: 0.24
- 역시 이 정도의 data_augmentation으로는
부족한가보다
- 결과
느낀점
- 작은 부분부터 차근차근 해결하는 방법 접근 방법이
딥러닝 모델 학습시킬 때 도움이 되는 것 같다. - meijieru/crnn.pytorch의 README.md 하단 문구를 보면
‘sort the image according to the text length’라는 문구가 있다.
개별 문자의 feature를 먼저 학습 시키는 쪽이
학습이 더 잘되어서 그런 것으로 추정한다. - ‘개선8: myfont의 가로 측 여백을 넓게 하여 학습 데이터 생성’이
효과적인 이유도 위 이유와 같다고 생각한다. - myfont의 가로 축 여백을 넓게 설정할 때 너비를 강제하는 것이기 때문에
1글자만 있는 이미지는 가로 축 여백이 많지만
4글자 모두 있는 이미지는 가로 축 여백이 이전과 비교하여 거의 늘어나지 않는다. - 그럼에도 불구하고 val_acc가 상승한 이유는
1글자 이미지에서 여백이 포함된 개별 문구의 CNN feature를
잘 추출했기 때문이라고 생각한다.
CRNN 학습 유의사항
- lr(learning rate)
- lr을 너무 키우면 loss가 점점 커져서 발산하여
모델 학습에 실패한다. - Building a custom OCR using pytorch(이하 OCR블로그) 에서
lr 기본 값은 0.001이었다. - 아마도 OCR블로그 문제에서
alphabet(영문, 특수문자 포함)이 나보다 훨씬 많기 때문에
초반 local minima 를 찾기 위해 비교적 큰 lr이 필요하지 않을까
생각한다.
- lr을 너무 키우면 loss가 점점 커져서 발산하여
- nClasses
- nClasses 수를 len(alphabet)로 하면
CTCLoss가 NaN이 되어 학습에 실패한다. - nClasses 수를 alphabet 수와 동일하게 하면
CTCLoss 계산 시 공란(-) 라벨이 없기 때문에
학습하지 못하고 발산하는 것으로 추정한다.
- nClasses 수를 len(alphabet)로 하면
- 그 외 CTCLoss 학습 실패 시
학습에 실패한 소스
- repository
- 원본 repository
- 설명
- github star가 가장 많은 CRNN repository이다.
- 문제
- torch 버전이 1.2로 굉장히 낮다
- 학습 및 추론 시 lmdb를 사용하여 데이터를 불러온다.
lmdb에 데이터를 전처리하여 넣는 코드가 있는데
python2를 사용 중이다. - CTCLoss는 빌드 시 gcc 5를 사용 중인데
ubuntu 14.04 에나 설치된 오래된 버전이라
사용하기 어렵다.
- 목표
- colab에서 사용할 수 있도록
python 3.9, torch 1.13 환경으로 포팅한다.
- colab에서 사용할 수 있도록
- 진행한 작업
- lmdb를 사용한 데이터 전처리 코드 python3에서 동작하도록 포팅
- crnn 코드 python3에서 동작하도록 포팅
- CTCLoss를 torch.nn.CTCLoss로 변경
- CRNN 모델에서 마지막 BiLSTM Layer의 outputs 크기를
11로 변경(0123456789 + 공란 수) - CRNN 모델 초기화 부분에서
학습된 Weight의 CNN 부분만 로드하도록 수정
- 결과
- 학습의 과정은 진행되는데
loss만 줄고 실제 예측값은 대부분 공란이다.
- 학습의 과정은 진행되는데