개요
- 카프카의 생산자(producer)의 메시지가
소비자에게 정확히 한 번만 배달되도록 할 수 있을까? - 결론은 소비자(consumer)의 작업이 카프카 내부에서만 이뤄진다면
정확히 한 번 메세지를 배달하는 것이 가능하다. - 하지만 소비자의 작업이 RDBMS와 같은 외부 저장소까지 포함한다면
정확히 한 번 메세지를 배달한다고 보장할 수 없다.
카프카란?
- 대용량 처리를 위한 메시지 지향 미들웨어이다[참고1].
대략적인 구조
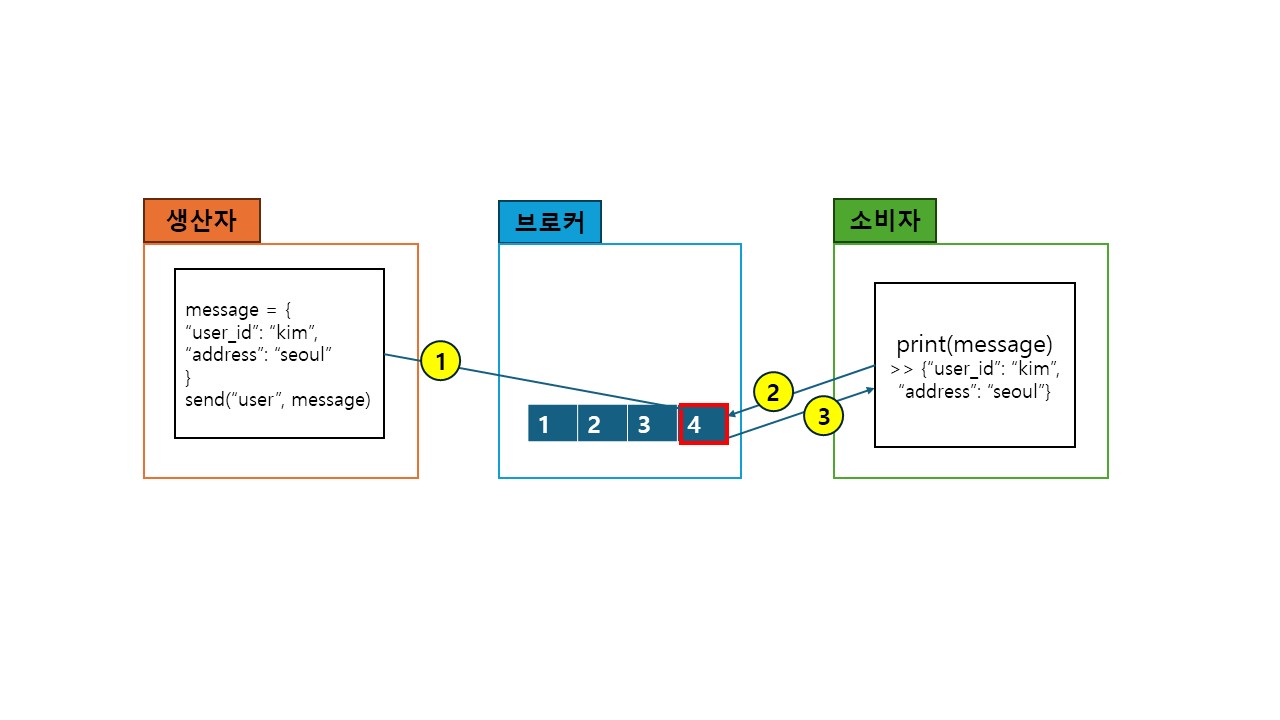
- 생산자(producer) - 브로커(broker) - 소비자(consumer)로 이뤄진다.
- 생산자에서 메세지를 생산하면 브로커에 저장된다.
- 소비자는 브로커에 저장된 메세지를 가져와 소비한다.
- 생산자와 소비자는 토픽으로 연결된다.
- 생산자1이 A토픽으로 메세지를 생성하면
브로커는 A토픽에 메세지를 저장한다. - 브로커에 A토픽이 저장되면
A토픽을 구독하고 있던 소비자1이 이를 가져와 소비한다. 
장점
- 비동기 처리를 통한 사용자 경험 개선
- 작업요청을 하는 생산자 부분과
요청 받은 작업을 처리하는 소비자 부분이 분리되어 있기 때문에
비동기 처리를 통하여 사용자 경험을 개선할 수 있다. - 예시 - 유저 생성 기능
- 가정
- 유저 생성 요청은 1초가 걸린다.
- 유저 생성이 10초가 걸린다.
- 동기적 구현
- 사용자는 유저 생성을 요청한 뒤
유저 생성 프로세스가 완료될 때까지
11초 간 대기하여야 한다.
- 사용자는 유저 생성을 요청한 뒤
- 비동기적 구현
- 사용자는 유저 생성을 요청하고
1초 뒤에 생성 요청 완료 응답을 받는다. - 이후 사용자는 화면에서 벗어나 다른 일을 할 수 있다.
- 10초 후에 유저 생성을 완료되면 사용자에게 알림이 전송된다.
- 사용자는 생성된 유저를 확인할 수 있다.
- 사용자는 유저 생성을 요청하고
- 가정
- 작업요청을 하는 생산자 부분과
- 서비스 간 결합도를 낮춰 유지 보수성을 늘린다.
- 카프카의 성질
- 다른 작업을 처리하는 소비자들이 동일한 토픽을 구독할 수 있다.
- 브로커에 저장된 메시지는 소비자가 소비를 하여도
없어지지 않고 일정 시간 동안 보관된다.
- 카프카를 도입하면 데이터는 카프카에 저장되고
서로 다른 여러 작업들은 담당 소비자가
카프카에서 데이터를 꺼내어 각자 처리하게 된다. - 이를 통하여 각 작업들과 연관성은 낮아지고
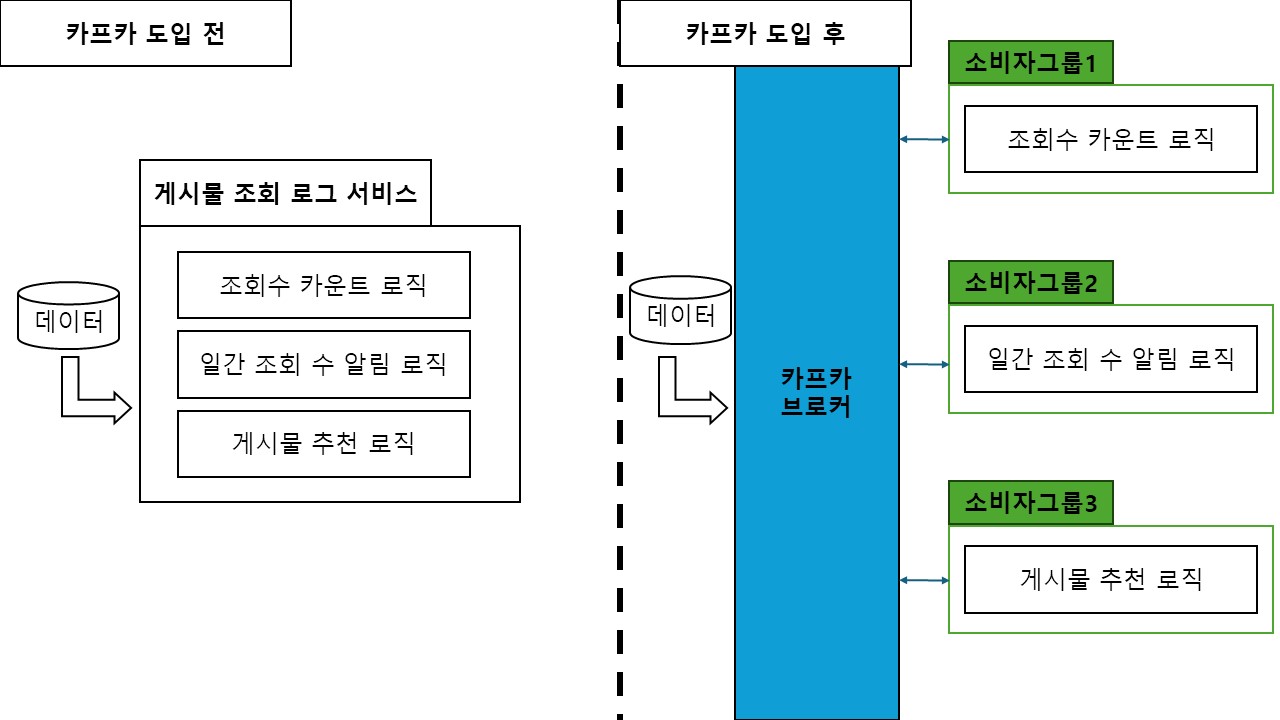
개별 작업의 문제 대응을 수월하게 할 수 있다[참고2]. - 예시 - 게시물 조회 로그
- 가정
- 메시지 - {사용자번호: 1, 게시물번호: 1}
- 소비자
- 조회 수 카운트 로직
- 일간 조회 수 알림 로직
- 게시물 추천 로직
- 카프카 도입 전
- 사용자가 게시물 조회
- 게시물 조회 로그 처리 컨트롤러에서 데이터 받음
- 게시물 조회 로그 처리 서비스에서 데이터를 처리
- 게시물 조회 로그를 이용한 작업이 추가될 수록
게시물 조회 로그 처리 서비스의 규모는 커진다.
- 카프카 도입 후
- 사용자가 게시물 조회
- 게시물 조회 로그 처리 컨트롤러에서
게시물 조회 로그 토픽에 데이터 저장(생산자) - 게시물 조회 로그 토픽에 데이터가 추가되면
각 소비자들은 데이터를 받아 작업 진행
- 카프카 도입 후 장점
- 게시물 추천 로직이 엄청 오래 걸리고 무거운 작업이라고 가정하자.
- 카프카 도입 전에는 한 서비스에 묶여있기 때문에
무거운 작업이 다른 작업에 부정적 영향을 끼치고 있음에도
이 작업을 분리하는데 어려움이 있다. - 반면 카프카를 도입한다면
해당 소비자 작업만 다른 서버로 분리시키고
작업 서버의 처리 성능을 높여 비교적 쉽게 대응이 가능하다.
- 가정
- 카프카의 성질
구조 - 브로커
- 카프카는 대용량 처리 상황을 대응하기 위해 만들어졌다.
- 이를 위해 내결함성과 고가용성을 확보하도록 설계되었다[참고3].
- 브로커는 분산 처리를 위하여 홀수 개의 3개 이상 서버로 구성된다.
- 브로커 서버 클러스터에서는 하나의 리더와 나머지 팔로워로 구성된다[참고4].
- 리더와 나머지 팔로워는 복제를 통하여 동일한 데이터를 갖게 된다.
- 선출된 리더가 모든 읽기와 쓰기를 진행한다.
- 리더가 동작하지 않으면 팔로워 중에서 새 리더를 선출한다.
구조 - 생산자와 acks
- acks는 생산자가 메시지를 브로커에 보냈을 때
응답에 따라 어떻게 행동할지를 결정한다[참고5][참고6]. - acks = 0
- 생산자는 리더에게 메세지를 전달하고
응답을 기다리지 않는다. - 처리량을 가장 빠르나 메세지 유실 가능성이 가장 높다.
- 생산자는 리더에게 메세지를 전달하고
- acks = 1
- 생산자는 리더에게 메세지를 전달하고
잘 받았는지 확인한다.
하지만 리더가 다른 팔로워들에게
메세지를 전달했는지 확인하지 않는다. - 처리량은 조금 느리나 메세지 유실 가능성은 현저히 줄어든다.
- 메세지 유실 상활
- 생산자가 리더에게 메세지 전달
- 리더가 생산자에게 메세지를 잘 받았다고 응답
- 리더가 팔로워에게 메세지를 전달하지 못하고 다운
- 메세지를 전달 받지 못한 팔로워가 리더로 선출
- 생산자는 리더에게 메세지를 전달하고
- acks = all(-1)
- 생산자를 리더에게 메세지를 전달하고 응답을 기다린다.
리더는 지정된 수의 팔로워에게 메세지를 복제한 후 리더에게 응답한다. - 처리량은 가장 느리나 메세지 유실 가능성은 가장 낮다.
- 생산자를 리더에게 메세지를 전달하고 응답을 기다린다.
구조 - 소비자
- 토픽과 파티션
- 토픽은 메세지를 구분하는 논리적 개념이다.
- 생산자가 브로커로 보낸 메세지는 지정된 토픽에 저장된다.
- 토픽은 파티션이라는 큐로 구현된다.
- 먼저 도착한 순으로 메세지가 순차적으로 파티션에 저장된다.
- 파티션과 소비자
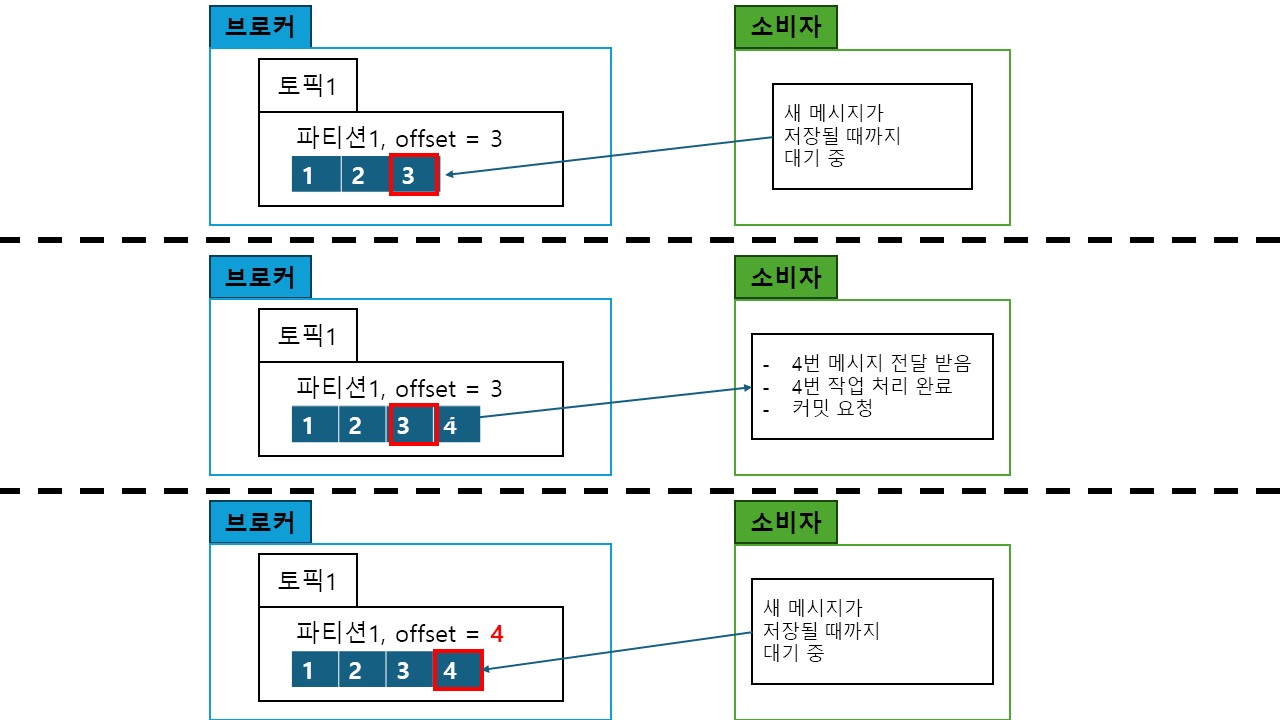
- 소비자는 파티션에 저장된 데이터를 순차적으로 꺼내온다.
- 소비자가 파티션에서 데이터를 꺼내더라도 데이터는 삭제되지 않는다.
- 대신 소비자가 소비를 마치면 커밋을 통해
처리를 마친 데이터를 표시(offset)할 수 있다.
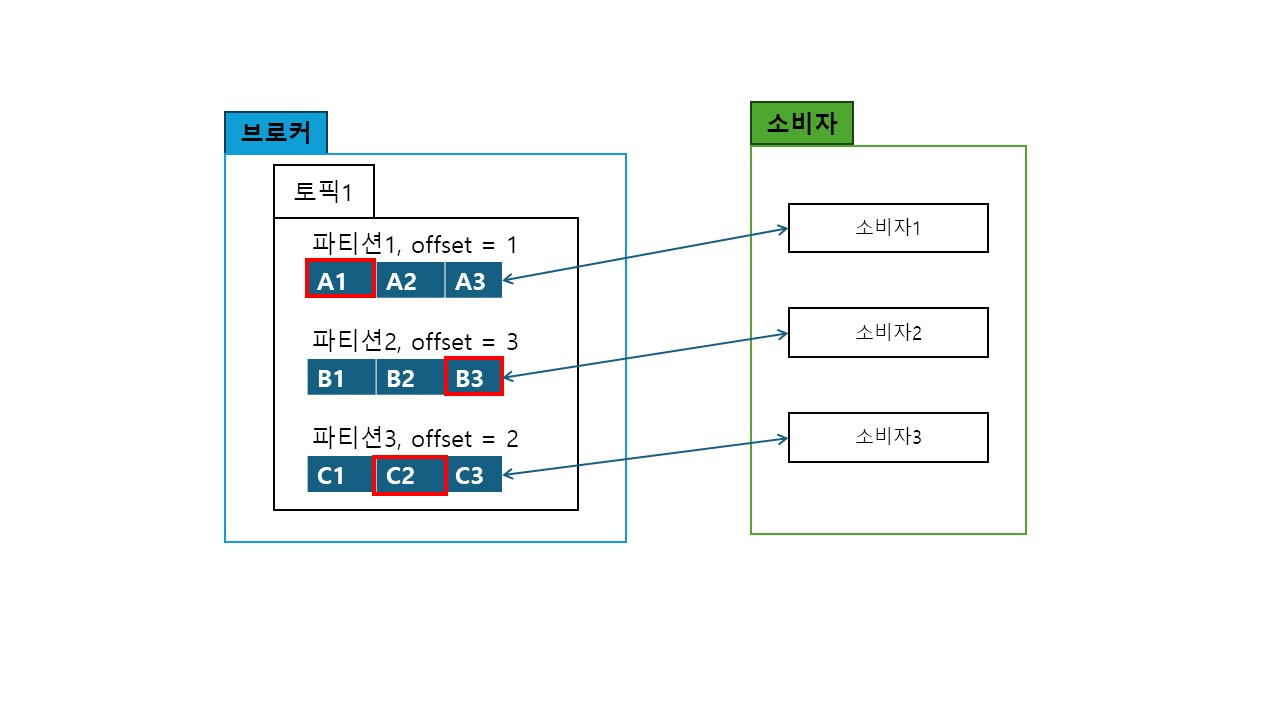
- 기본적으로 파티션과 소비자는 1:1이다.
- 만약 소비자 작업이 무거워
처리해야할 작업들이 쌓인 상태라면
파티션을 추가하여 병렬로 작업을 처리해 처리량을 늘릴 수 있다.
- 파티션은 한 번 추가하면 다시 되돌릴 수 없기 때문에
신중하게 추가하여야 한다.
- auto commit
- enable.auto.commit이 true이면 소비자의 작업 완료와 상관없이
auto.commit.interval.ms 후에 자동으로 커밋한다. - 작업이 오래걸려 실패하는 경우에도 커밋되어
메세지가 유실될 수 있다. - 그러므로 enable.auto.commit을 false 처리하고
소비자에서 작업 완료 후 수동 커밋한다.
- enable.auto.commit이 true이면 소비자의 작업 완료와 상관없이
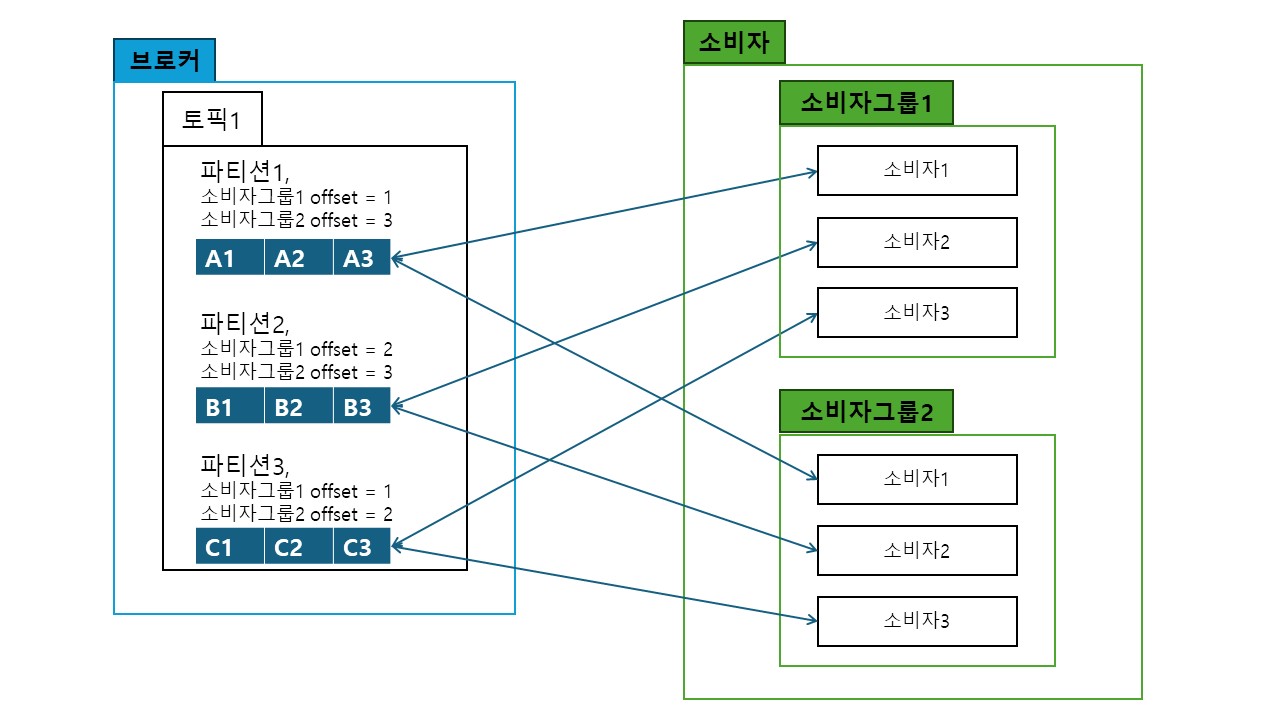
- 소비자 그룹
트랜잭션
- 트랜잭션을 사용하면 생산자의 메세지가
브로커에 중복 저장되는 것을 막을 수 있다[참고9][참고10]. - 각 메세지는 시퀀스 번호가 포함된다.
- 리더가 실패하더라도 새로 선출된 리더는
이 시퀀스 번호를 확인하여 중복 메세지 여부를 판단한 뒤
문제가 없는 경우 트랜잭션 커밋을 하게 된다. - 소비자는 isolation.level = read_committed 로 설정하여
트랜잭션 커밋된 메시지만 받도록 설정할 수 있다.
RDBMS와 같은 외부 저장소 작업이 포함된 소비자의 정확히 한 번 처리
- 위와 같은 구성을 준비한 뒤에 카프카 내에서 작업을 하는 경우
정확히 한 번 처리를 구현할 수 있다. - 그러나 RDBMS와 같은 외부 저장소 작업이 포함된다면
정확히 한 번 처리를 보장할 수 없다. - 예시 - 정확히 한 번 실패
- 소비자에서 RDBMS 저장 작업이 완료
- 브로커에게 수동 커밋 요청
- 네트워크 문제로 수동 커밋 요청 증발
- 일정 시간이 지나자 브로커에서
해당 소비자 작업을 실패로 처리 - 다른 소비자 인스턴스에서 문제의 오프셋을 다시 읽고
이를 성공할 경우 RDBMS에 중복 데이터 기록
해결 방안
- 외부 저장소에서 중복 방지 로직 구현
- 고유키를 지정하여 중복된 데이터가
쓰이지 않도록 처리한다.
- 고유키를 지정하여 중복된 데이터가
- 카프카 connect를 이용
- RDBMS에 저장해야하는 데이터를
카프카의 다른 토픽에 저장한다. - 이는 카프카 내부 처리이므로
정확히 한 번 처리된다. - 결과가 저장된 토픽을
카프카 connect를 이용하여
RDBMS에 전송시킨다.
- RDBMS에 저장해야하는 데이터를
참고
- 참고1 - 메시지 지향 미들웨어
- 참고2 - 결합도
- 참고3 - 내결함성 vs 고가용성
- 참고4 - [Kafka] Replication(리플리케이션)과 Leader(리더)와 Follower(팔로워)를 알아보자
- 참고5 - Kafka 운영자가 말하는 Producer ACKS
- 참고6 - 4.6 Message Delivery Semantics
- 참고7 - Kafka Partitions and Consumer Groups in 6 mins
- 참고8 - Class KafkaConsumer<K,V>
As a multi-subscriber system, Kafka naturally supports having any number of consumer groups for a given topic without duplicating data (additional consumers are actually quite cheap). - 참고9 - [Kafka] 프로듀서가 정확히 한 번만 전송하는 방식
- 참고10 - Exactly-Once Semantics Are Possible: Here’s How Kafka Does It